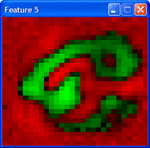
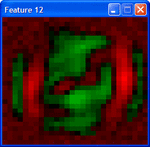
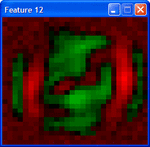
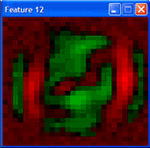
Here are features from patches of weights in the second layer of a DBN trained with contrastive divergence and fine tuned with conjugate gradients. These features are high level representations of price patterns. Very powerful stuff. The only concern and not the least would be to devise an online version of the training process so that we can use them in trading. I am not aware that online learning exists for deep structures.
Sorry got to close a position...
I don't see why an online version could not be done. Conceptually you could do it with two Dll's, one to train and one to classify as follows:
Arrays/structures:
Rates array.. contains OHLCV for each bar
Target array..contains results if entry on a given bar
Input array
Net
MT4
Allocates memory for all structures (This is so that strategy tester will work. )
Maintains rates and Target array
Calls Net_Train with pointers to arrays
Calls Net_Classify with pointers to arrays
Uses result to trade
Net_Train
Calls feature_builder to build input array
Uses target array to label input array
Trains Net
Net_Classify
Calls feature_builder to update input array
Applies net to determine prediction
Feature_Builder
Calculates input to net .. indicators, conditions to build input array
Operation:
MT4 initializes the net by calling Net_Train
At end of each bar:
If a new label has been determined, MT4 calls Net_Train to update input array and retrain the net.
MT4 calls Net_Classify to get a prediction
MT4 makes appropriate trading decisions.
This all assumes that a net_train dll could run in 1 bar time. If not, then the training would have to go on in the background while new input was collected. Would require some double buffering.
Those are intriguing pictures of hidden structure.:clap: What is the nature of the input price patterns, and the DBN used to find them? I assume unsupervised learning for this level?