I apologize I did not check the link.
This is the site of John Conover:
NtropiX: Home
Subject: Stock Market
High Frequency is right. There is no correlation between the price direction and the the movement of the indicator.
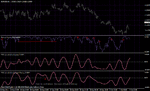
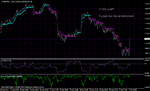
The basic pattern the indicator gives is a drop of entropy. The idea is when there is a drop of entropy something is happening, something is going on.
Theoretically this can be used as a confirmation of a technical break - out. For example if the price goes beyond our break - out level and that is accompanied with a drop of entropy this is a kind of a filter that the break - out is good.
Here I add another derivative that is calculating the entropy surprise. This is from the thread on TSD (Digital ASCTrend) and Forex factory (Optimized trend trading) , but I wanted to share it everywhere.
I did on TSD to use the Kositsin library in order to use the Jurik smoothing of the entropy function. Really nice indicator.
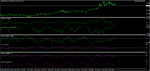
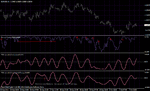
The other possibility is to use the entropy to adapt your directionnal algorythms. For example I used to adapt the SSA end-pointed normalized. I just devided the readings of the SSA by the entropy. So when the entropy is getting lower the readings will be bigger. So I had very big readings (oscillations when the entropy was small enough and smaller when the entropy is bigger.)
On the shot I show the difference between ssa normalized end pointed and ssa normalized end pointed with entropy adaptation (of course you can find other forms of adaptation, what I did is just a basic thing).
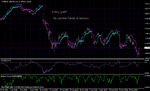
Here the surprise is -MathLog (P)); Bigger values equal more surprise. No idea how to trade.